Programmers can be an odd lot - we can have a perfectly good tool available to us and we still yearn to build our own version of it. In this case, Google Authenticator was released back in 2010 and has been my primary tool to satisfy Mutli-Factor Authentication for many applications. This particular two-step verification process uses the Time-based One-time Password Algorithm (TOTP) to generate 6 digit pin codes offering a second piece of authentication.
Even though the Google Authenticator app is likely used by millions of people around the world, I have always wanted to write my own version of it. One main reason is that I want a Windows based client application that works in conjunction with the mobile application and shares the same database. I definitely favor working on a desktop as I am much more productive at a desk using a mouse and keyboard versus a tablet or a mobile phone. I find it somewhat distracting and less productive to be required to use my phone when I am working at my desk. I simply want a tray application to easily give me the requested required pin number.
I am sure there are solutions out there that work with Windows desktop and mobile phones, but I haven’t found any so far that I liked, so I have decided to write my own. The first stumbling block is that implementations rely on a base32 encoded secret key and base32 encoding is not a popular method and is not supported in the RTL or in the popular DelphiEncryptionCompedium library. There are other implementations of this encoding process out on the web, but I didn’t like the code for various reasons. So again, I wanted to write my own simple base32 coder. (I suspect a trend here!)
Technically speaking, base32 is not specified in the RFC specifications for TOTP. However, it is the industry standard method for encoding the secret key within the QR Code link and is also typically used to store the secret key to disk. TOTP is covered in RFC-6238 which relies on the HMAC-Based One-Time Password Algorithm (HOTP) as defined in RFC-4226. Base32 is covered in RFC-4648, The Base16, Base32, and Base64 Data Encodings document. (Note that you may see some references to RFC-3548, but as this StackOverflow answer states, RFCs 3548 and 4648 are basically the same with only minor edits.)
You can browse the source of Google-Authenticator on GitHub, and see its open source alternative, FreeOTP. (Google stopped publishing the source of the Android based Google Authenticator which apparently sparked the generation of the FreeOTP project.)
Base32 Encoding in Delphi
From the RFC
The Base 32 encoding is designed to represent arbitrary sequences of octets in a form that needs to be case insensitive but that need not be human readable. A 33-character subset of US-ASCII is used, enabling 5 bits to be represented per printable character. (The extra 33rd character, “=”, is used to signify a special processing function.)
Since there are only 32 characters in the base32 alphabet, each character can be represented with 5 bits of data. We will need to convert every 8-bit input byte to a 5-bit base32 output character, so it will always take more than one encoded output character to represent a single byte of input which makes base32 encoding very inefficient for storage. However, it does have advantages as it the result can be safely used without further encoding within filenames and URIs (without the padding character) and the output is always in uppercase which helps with case-sensitive storage systems. The alphabet was also constructed to exclude the most commonly misidentified characters: 0, 1, and 8.
Here is the interface definition of my TBase32 class as originally implemented. You can see the base32 dictionary defined, the PadCharacter and simple Encode/Decode overloaded methods taking string, TBytes, or pointer+length inputs.
1
2
3
4
5
6
7
8
9
10
11
12
13
TBase32 = class
public const
Dictionary:AnsiString = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ234567'; // 32 characters, max Base2 of 5 digits '11111' (Base32 encoding uses 5-bit groups)
PadCharacter:Integer = 61; // Ord('=');
public
class function Encode(const pPlainText:string):string; overload;
class function Encode(const pPlainText:TBytes):TBytes; overload;
class function Encode(const pPlainText:Pointer; const pDataLength:Integer):TBytes; overload;
class function Decode(const pCipherText:string):string; overload;
class function Decode(const pCipherText:TBytes):TBytes; overload;
class function Decode(const pCipherText:Pointer; const pDataLength:Integer):TBytes; overload;
end;
Encoding string inputs assume UTF-8 by default as that is what the internet uses today and the prover and verifier must always match input values. You can use either of the other two Encode overloaded methods if you want to encode the input value as-is without modification.
These are the two simple overloaded Encode methods which simply forward their calls to the main underlying Encode method.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class function TBase32.Encode(const pPlainText:string):string;
begin
// always encode UTF8 by default to match most implementations in the wild
Result := TEncoding.UTF8.GetString(Encode(TEncoding.UTF8.GetBytes(pPlainText)));
end;
class function TBase32.Encode(const pPlainText:TBytes):TBytes;
var
vInputLength:Integer;
begin
SetLength(Result, 0);
vInputLength := Length(pPlainText);
if vInputLength > 0 then
begin
Result := Encode(@pPlainText[0], vInputLength);
end;
end;
Below is the source of the main Encoding method. We loop through all input bytes, processing the input in 5-bit chunks. For every 5 bits received, we will output the ordinal position of the corresponding base32 character found in the dictionary into a bit-buffer. Left over bits are carried forward and combined with the next byte to output the next base32 character. Once we have processed all input bytes, if we have any more bits in the buffer it is padded with zeros to output the final character value. Finally, depending on the input size we will add 0 to 6 padding characters to have an output size evenly divisible by 5 bits. (This output padding is optional in many implementations.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
class function TBase32.Encode(const pPlainText:Pointer; const pDataLength:Integer):TBytes;
var
vBuffer:Integer;
vBitsInBuffer:Integer;
vDictionaryIndex:Integer;
vFinalPadBits:Integer;
vSourcePosition:Integer;
vResultPosition:Integer;
i:Integer;
vPadCharacters:Integer;
begin
SetLength(Result, 0);
if pDataLength > 0 then
begin
// estimate max bytes to be used (excess trimmed below)
SetLength(Result, Trunc((pDataLength / 5) * 8) + 6 + 1); // 8 bytes out for every 5 in, +6 padding (at most), +1 for partial trailing bits if needed
vBuffer := PByteArray(pPlainText)[0];
vBitsInBuffer := 8;
vSourcePosition := 1;
vResultPosition := 0;
while ((vBitsInBuffer > 0) or (vSourcePosition < pDataLength)) do
begin
if (vBitsInBuffer < 5) then // fill buffer up to 5 bits at least for next (possibly final) character
begin
if (vSourcePosition < pDataLength) then
begin
// Combine the next byte with the unused bits of the last byte
vBuffer := (vBuffer shl 8) or PByteArray(pPlainText)[vSourcePosition];
vBitsInBuffer := vBitsInBuffer + 8;
vSourcePosition := vSourcePosition + 1;
end
else
begin
vFinalPadBits := 5 - vBitsInBuffer;
vBuffer := vBuffer shl vFinalPadBits;
vBitsInBuffer := vBitsInBuffer + vFinalPadBits;
end;
end;
// Map 5-bits collected in our buffer to a Base32 encoded character
vDictionaryIndex := $1F and (vBuffer shr (vBitsInBuffer - 5)); // $1F mask = 00011111 (last 5 are 1)
vBitsInBuffer := vBitsInBuffer - 5;
vBuffer := ExtractLastBits(vBuffer, vBitsInBuffer); // zero out bits we just mapped
Result[vResultPosition] := Ord(TBase32.Dictionary[vDictionaryIndex + 1]);
vResultPosition := vResultPosition + 1;
end;
// pad result based on the number of quantums received (should be same as: "Length(pPlainText)*BitsPerByte mod BitsPerQuantum of" 8:16:24:32:)
case pDataLength mod 5 of
1:
vPadCharacters := 6;
2:
vPadCharacters := 4;
3:
vPadCharacters := 3;
4:
vPadCharacters := 1;
else
vPadCharacters := 0;
end;
for i := 1 to vPadCharacters do
begin
Result[vResultPosition + i - 1] := TBase32.PadCharacter;
end;
// trim result to actual bytes used
SetLength(Result, vResultPosition + vPadCharacters);
end;
end;
Manual Base32 Encoding Example
To help reinforce the concept of the code above, let us walk through an example by manually encoding the word Delphi. Below is an image displaying the overall process.
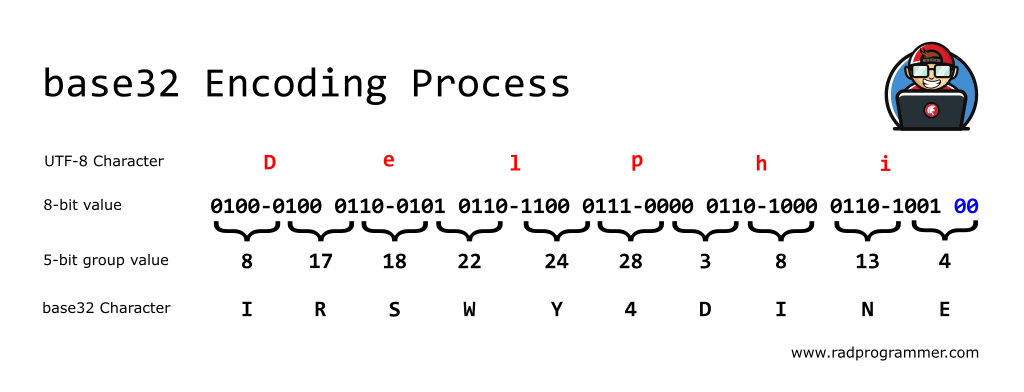
Here is a table of the characters that make up this input text and their corresponding values in Decimal and Binary (base2) representation.
| Character | Decimal Value | Binary |
|---|---|---|
| D | 68 | 0100-0100 |
| e | 101 | 0110-0101 |
| l | 108 | 0110-1100 |
| p | 112 | 0111-0000 |
| h | 104 | 0110-1000 |
| i | 105 | 0110-1001 |
| Input byte stream for the word Delphi |
|---|
| 0100-0100 0110-0101 0110-1100 0111-0000 0110-1000 0110-1001 |
We will now encode these input bytes into their base32 representation. (Note that you can obviously encode any binary value into base32 as we encode byte values and not characters.) All base32 encoded values are represented by a specific set of output characters making up the base32 Alphabet as shown below:
| base32 Alphabet (0-based index) |
|---|
| ABCDEFGHIJKLMNOPQRSTUVWXYZ234567 |
We need to split up our input byte stream into 5-bit groups for base32 encoding. Start at the left and extract 5 bits at a time. You can then take the decimal value of this 5-bit group and use it as an index value of a specific character from the base32 alphabet. (If there are trailing bits that fail to make up a full 5-bit group, we will need to right-pad those bits with zeros as shown in the last entry below.)
| Binary 5-bit group | Decimal Value | base32 Character |
|---|---|---|
| 01000 | 8 | I |
| 10001 | 17 | R |
| 10010 | 18 | S |
| 10110 | 22 | W |
| 11000 | 24 | Y |
| 11100 | 28 | 4 |
| 00011 | 3 | D |
| 01000 | 8 | I |
| 01101 | 13 | N |
| 001 Pad remaining bits with zeros for a full 5-bit group 00100 | 4 | E |
Therefore, the base32 encoding of the word Delphi is: IRSWY4DINE. According to the RFC, base32 representations are to be padded with a special character (‘=’) to ensure an even number of 8-character groups (representing 40-bit quantums.) In this example, since we have 10 characters of output, we will need to extend the result with 6 padding characters for the final RFC-compatible result of IRSWY4DINE====== (which is two full sets of 8-character groups.)
Since base32 has excluded the letters 0,1 and 8 there should be no doubt that the first and eighth characters in the output are the letter I and not the number 1.
Base32 Decoding in Delphi
As with encoding, the first two overloaded decoding methods simply forward the data to the more advanced Decode method. Again, string-based inputs are assumed to be in UTF-8 format.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class function TBase32.Decode(const pCipherText:string):string;
begin
// always decode UTF8 by default to match most implementations in the wild
Result := TEncoding.UTF8.GetString(Decode(TEncoding.UTF8.GetBytes(pCipherText)));
end;
class function TBase32.Decode(const pCipherText:TBytes):TBytes;
var
vInputLength:Integer;
begin
SetLength(Result, 0);
vInputLength := Length(pCipherText);
if vInputLength > 0 then
begin
Result := Decode(@pCipherText[0], vInputLength);
end;
end;
The decoding method reads in every base32 encoded character and looks up its position in the dictionary to determine the original 5-bit value. This value is stored in a bit-buffer and once we have read in at least 8-bits we can then restore it to its original input byte value. The remaining bits are combined with future 5-bit values and the process continues until we have read in all encoded characters.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class function TBase32.Decode(const pCipherText:Pointer; const pDataLength:Integer):TBytes;
var
vBuffer:Integer;
vBitsInBuffer:Integer;
vDictionaryIndex:Integer;
vBase32Char:AnsiChar;
vSourcePosition:Integer;
vResultPosition:Integer;
begin
SetLength(Result, 0);
if pDataLength > 0 then
begin
// estimate max bytes to be used (excess trimmed below)
SetLength(Result, Trunc(pDataLength / 8 * 5)); // 5 bytes out for every 8 input
vSourcePosition := 0;
vBuffer := 0;
vBitsInBuffer := 0;
vResultPosition := 0;
repeat
vBase32Char := AnsiChar(PByteArray(pCipherText)[vSourcePosition]);
vDictionaryIndex := Pos(vBase32Char, TBase32.Dictionary); // todo: support case insensitive decoding?
if vDictionaryIndex = 0 then
begin
// todo: Consider failing on invalid characters with Exit(EmptyStr) or Exception
// For now, just skip all invalid characters.
// If removing this general skip, potentially add intentional skip for '=', ' ', #9, #10, #13, '-'
// And perhaps auto-correct commonly mistyped characters (e.g. replace '0' with 'O')
vSourcePosition := vSourcePosition + 1;
Continue;
end;
vDictionaryIndex := vDictionaryIndex - 1; // POS result is 1-based
vBuffer := vBuffer shl 5; // Expand buffer to add next 5-bit group
vBuffer := vBuffer or vDictionaryIndex; // combine the last bits collected and the next 5-bit group (Note to self: No mask needed on OR index as its known to be within range due to fixed dictionary size)
vBitsInBuffer := vBitsInBuffer + 5;
if vBitsInBuffer >= 8 then // Now able to fully extract an 8-bit decoded character from our bit buffer
begin
vBitsInBuffer := vBitsInBuffer - 8;
Result[vResultPosition] := vBuffer shr vBitsInBuffer; // shr to hide remaining buffered bits to be used in next iteration
vResultPosition := vResultPosition + 1;
vBuffer := ExtractLastBits(vBuffer, vBitsInBuffer); // zero out bits already extracted from buffer
end;
vSourcePosition := vSourcePosition + 1;
until vSourcePosition >= pDataLength; // NOTE: unused trailing bits, if any, are discarded (as is done in other common implementations)
// trim result to actual bytes used (strip off preallocated space for unused, skipped input characters)
SetLength(Result, vResultPosition);
end;
end;
The routines rely on bit-shifting with the built-in shr/shl routines and also an ExtractLastBits utility method to help manage the bit-buffer. There may be better ways of doing this but I wanted a simple way to extract a specific number of right most bits from an integer value. We are applying a mask of all zeros ending with a number of ones matching the number of bits desired.
This can be better understood by looking at the input value of 14 (Base2 of ‘0000-1110’) and sample calls to ExtractLastBits to extract the right most number of bits of the input value (padded left with zeros):
| Input Value | BitsToExtract | Result (Integer) | Base2 Result |
|---|---|---|---|
| 14 | 1 | 0 | ‘0000-0000’ |
| 14 | 2 | 2 | ‘0000-0010’ |
| 14 | 3 | 6 | ‘0000-0110’ |
| 14 | 4 | 14 | ‘0000-1110’ |
Base32 Encoding Unit Tests
RFC-4648 provides test vectors to validate our custom implementation which can easily be implemented in two DUnit tests as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
procedure TBase32Test.TestEncodingRFCVectors;
begin
CheckEquals('', TBase32.Encode(''));
CheckEquals('MY======', TBase32.Encode('f'));
CheckEquals('MZXQ====', TBase32.Encode('fo'));
CheckEquals('MZXW6===', TBase32.Encode('foo'));
CheckEquals('MZXW6YQ=', TBase32.Encode('foob'));
CheckEquals('MZXW6YTB', TBase32.Encode('fooba'));
CheckEquals('MZXW6YTBOI======', TBase32.Encode('foobar'));
end;
procedure TBase32Test.TestDecodingRFCVectors;
begin
CheckEquals('', TBase32.Decode(''));
CheckEquals('f', TBase32.Decode('MY======'));
CheckEquals('fo', TBase32.Decode('MZXQ===='));
CheckEquals('foo', TBase32.Decode('MZXW6==='));
CheckEquals('foob', TBase32.Decode('MZXW6YQ='));
CheckEquals('fooba', TBase32.Decode('MZXW6YTB'));
CheckEquals('foobar', TBase32.Decode('MZXW6YTBOI======'));
end;
Next Steps
We now have everything needed to implement base32 encoding in Delphi! This code will be used later in this blog series dedicated to building a custom RADAuthenticator app intended to replace the Google Authenticator app. Part 2 will focus on implementing the TOTP algorithm.
The code is released as Open Source under the Apache-2.0 license and is found within the rad-authenticator repository under my RADProgrammer organization on GitHub. (I plan to use this RADProgrammer organization for future RAD Studio related projects.) I would like to eventually get this project on the Google, Apple, and Microsoft app stores while blogging about various aspects of the process. I currently do not have an app published on the play stores and is simply another task I have wanted to do for a long time. And since I now have a blog, I can make very public stupid mistakes while attempting to do so! (Making mistakes is the best way to learn.) Again, sometimes programmers can be an odd lot and I certainly claim to be within that group.
I think the Delphi community would also benefit from a cross-platform app built from Delphi which solves a common real-world task and has everything available to build that app available online. I welcome any input from anyone wanting to contribute to the project in any way, even if only to criticize the code.
I have setup a RADProgrammer chat space on Discord dedicated to RADProgrammer projects such as this. Here is an invitation link to join this Discord. See you online!